Simulation Demo

RL-trained drone landing on a flexible tree branch and maintaining stable contact (K=100)
Problem Setup
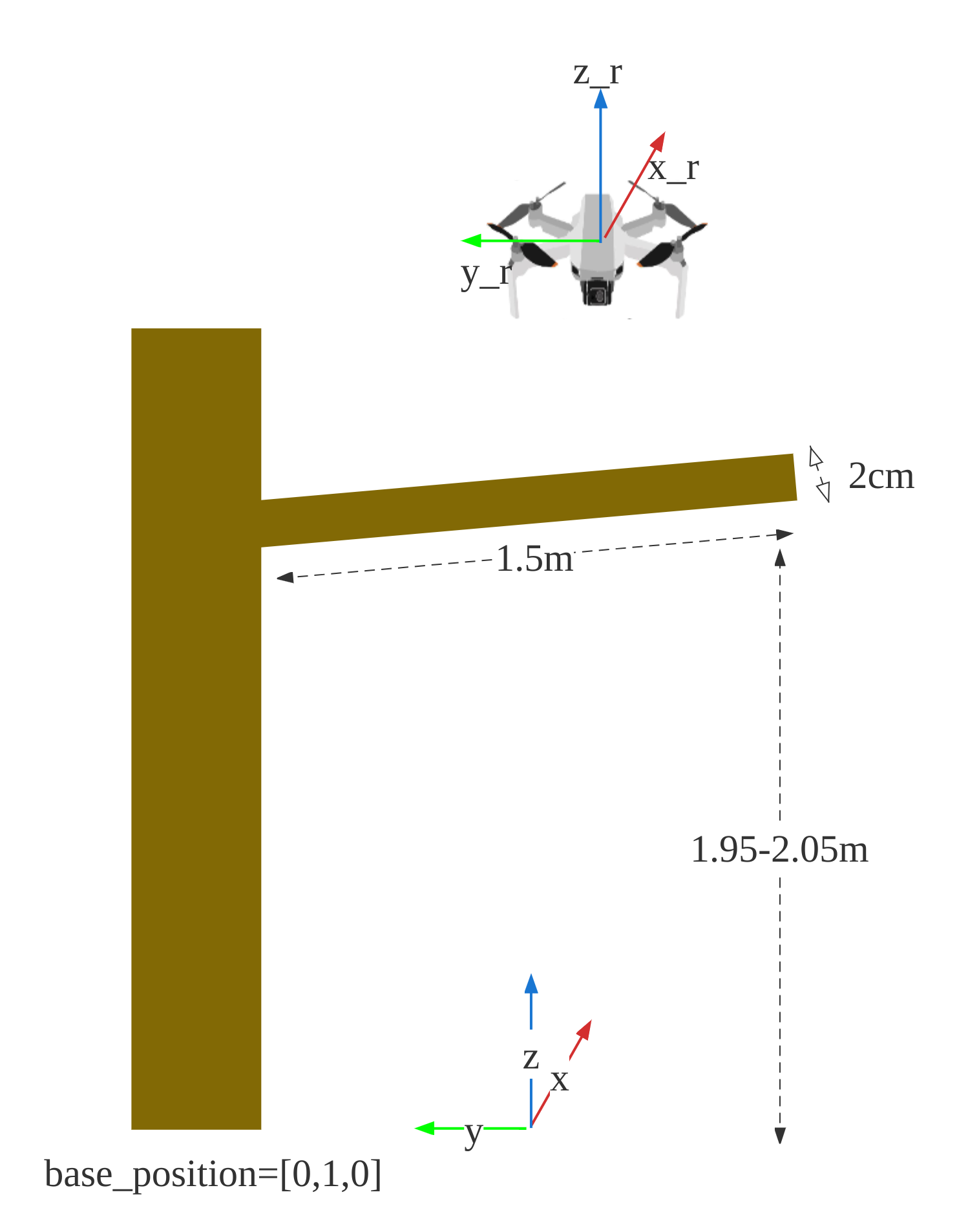
Simulation environment — drone positioned above a 1.5m flexible branch, randomized initial position and branch stiffness

Branch modeled with PD-controlled joints — stiffness varied across training episodes
- Goal: land a drone on flexible tree branches and maintain stable contact — for environmental monitoring and sample collection
- Challenge: the branch deforms upon contact, requiring the drone to adapt its thrust and attitude in real time
- Domain randomization: branch stiffness, initial drone position, and branch orientation randomized during training
Method
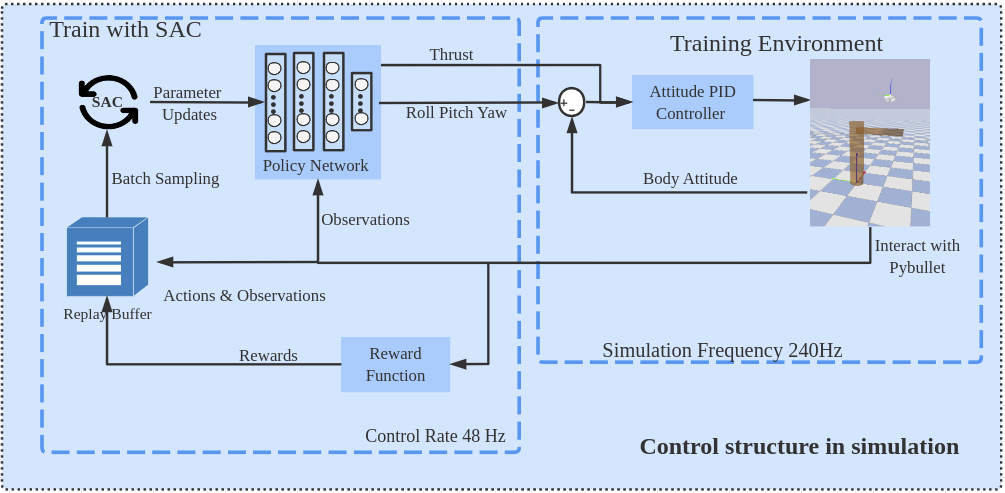
Training pipeline — PPO/SAC agent outputs thrust and reference attitude, low-level PD controller tracks commands at 48Hz
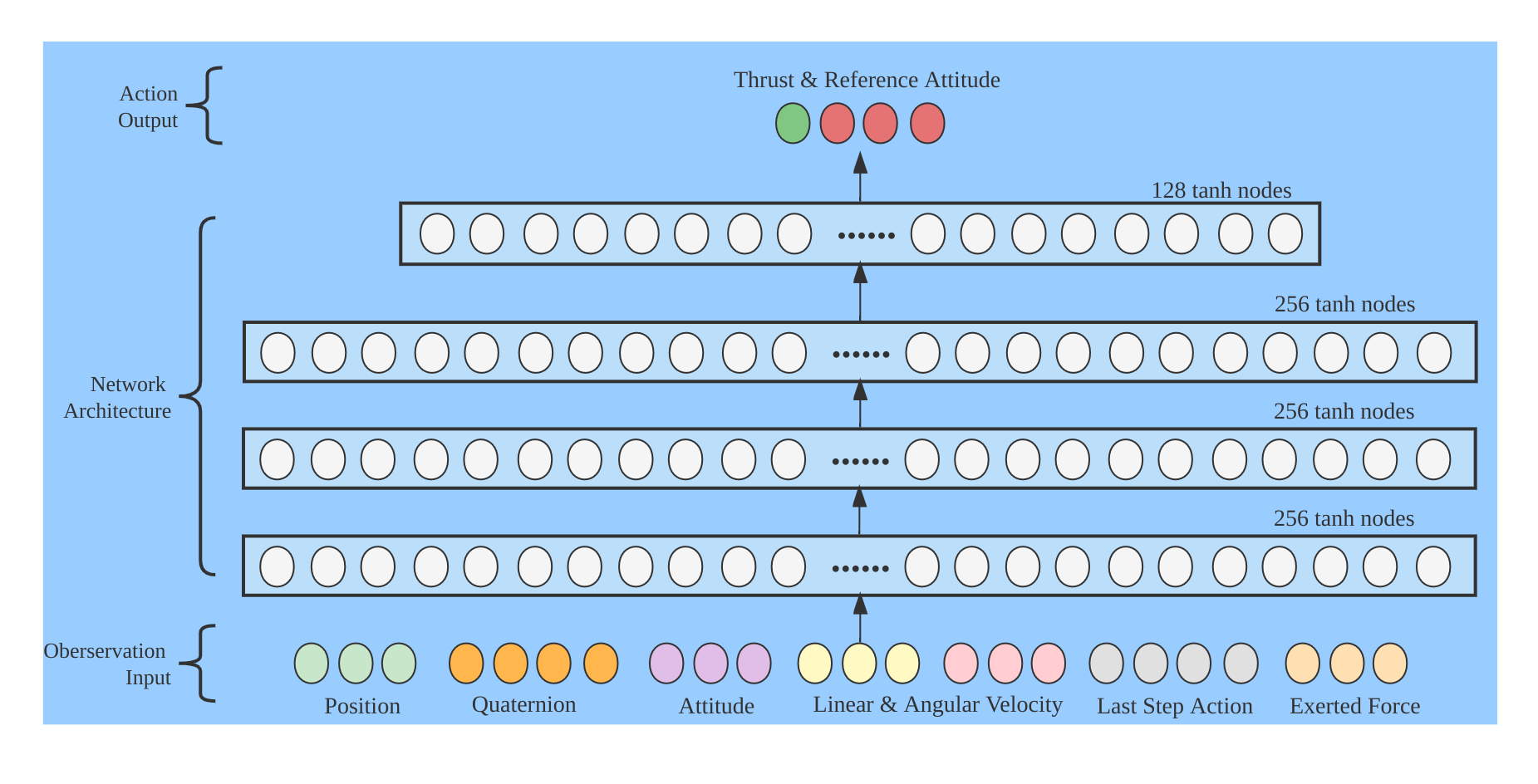
Policy network — 4-layer MLP [256, 256, 256, 128] with tanh activation. Inputs: position, attitude, velocity, external force. Outputs: thrust + reference attitude
Training

Training curves — SAC converges in ~6h (reward ~0.85), PPO in ~14h. Both using Stable-Baselines3
Evaluation — Different Branch Stiffness

K = 1 — very soft branch

K = 10 — soft branch

K = 100 — medium stiffness

K = 1000 — stiff branch
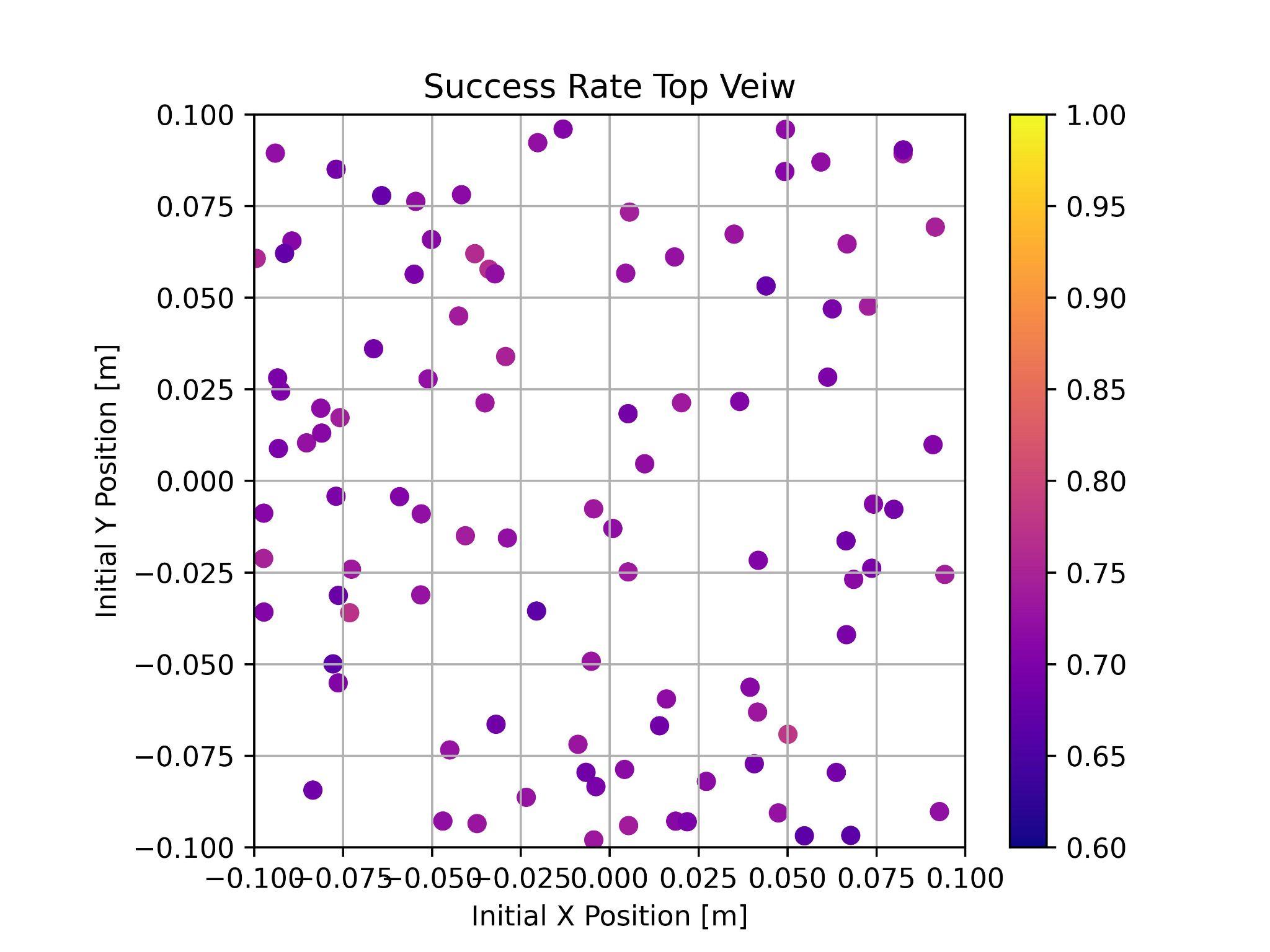
Success rate across initial positions (PPO, K=1) — dot position = initial XY, color = success rate
Contributions
- Built an RL framework for training aerial physical interaction with flexible structures
- Demonstrated that RL can control a drone to land on and maintain contact with deformable tree branches
- Compared PPO and SAC — SAC converges faster and achieves higher reward
- Evaluated across four branch stiffness levels (K = 1, 10, 100, 1000) with 100 randomized trials each
- Defined quantitative metrics: success rate, stability, contact force, and z-displacement